
Have you ever found yourself scrolling through a streaming service, only to stumble upon a show or movie that feels uncannily perfect for your mood? It’s almost as if the platform peered directly into your mind, anticipating your next binge. While it might seem like digital sorcery, this isn’t magic at play; it’s the sophisticated dance of algorithms, meticulously designed to understand and predict your entertainment desires.
Behind every ‘Recommended for You’ carousel lies a complex system constantly sifting through vast oceans of data. These systems are the unsung heroes of your personalized viewing experience, transforming a potentially overwhelming library into a curated collection tailored just for your unique tastes.
Before we dive deep into the fascinating world of algorithmic recommendations, take a quick peek at our YouTube Shorts video that briefly touches upon this very topic:
Intrigued? Let’s pull back the curtain and explore the genius behind how streaming services decide what to recommend to you.
Table of Contents
The Digital Fingerprint: Analyzing Your Every Move
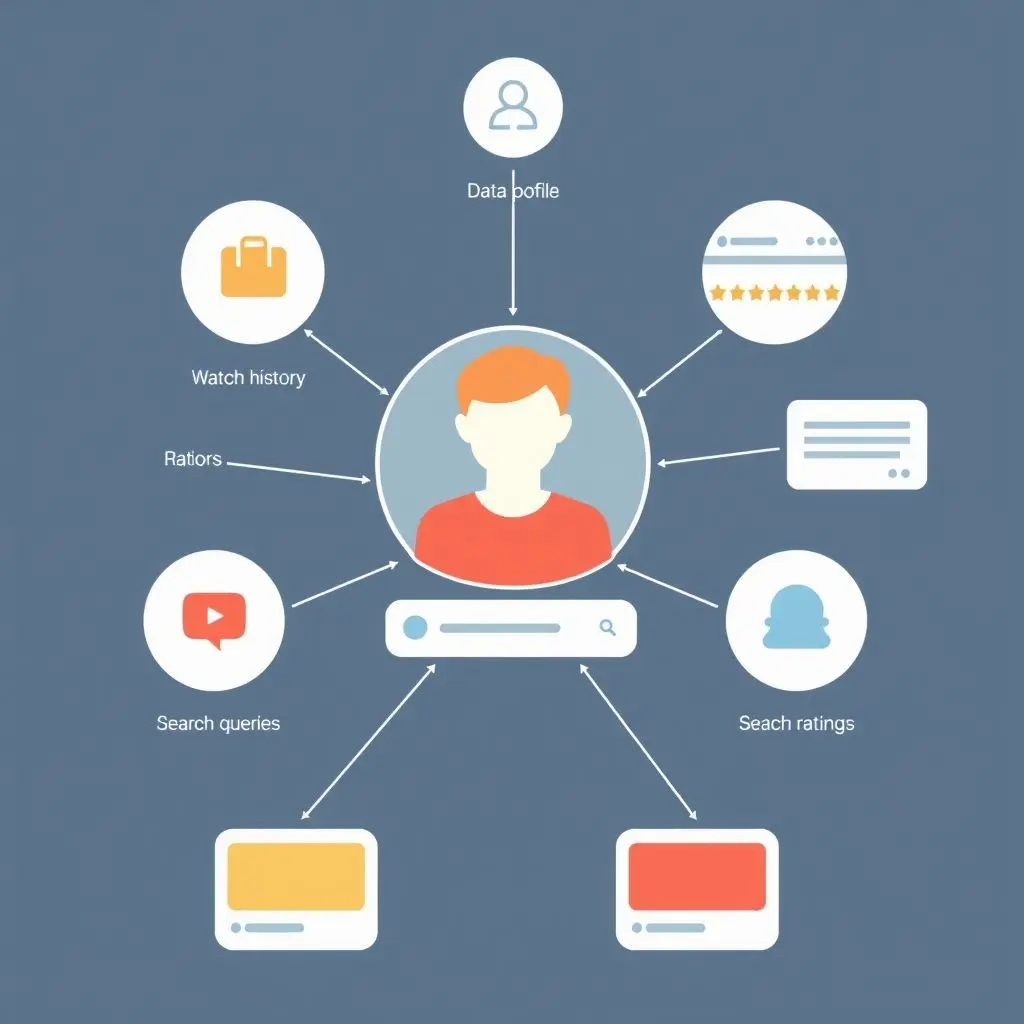
The foundation of any robust recommendation engine is data, and lots of it. Every interaction you have with a streaming platform leaves a digital fingerprint, offering invaluable clues about your preferences. These services are less interested in *what* you watch in isolation and more in the intricate *patterns* of your consumption.
What Data Points Do They Collect?
- Viewing History: This is the most obvious. What shows and movies have you watched? What genres do they belong to? Which actors, directors, or themes are prevalent?
- Watch Time & Completion Rates: Did you finish a series? Or did you abandon a movie after 10 minutes? Completing content signals enjoyment, while early abandonment suggests disinterest.
- Searches & Hovers: What did you search for, even if you didn’t watch it? How long did your cursor or finger linger over a particular title before moving on? This indicates interest or curiosity.
- Ratings & Likes/Dislikes: Explicit feedback is gold. Your direct input helps calibrate the algorithm’s understanding of your taste.
- Skips & Rewinds: Skipping intro sequences or rewinding to re-watch a scene provides micro-signals about what you find engaging or uninteresting.
- Device & Time of Day: Do you prefer documentaries on your tablet during your commute, but action movies on your smart TV on weekends? Context matters.
These data points, seemingly disparate, are woven together to create a comprehensive profile of your viewing habits. This profile then becomes the basis for prediction.
The Two Pillars of Recommendation: Collaborative & Content-Based Filtering
While gathering data is crucial, the real genius lies in how that data is processed. Most streaming services rely on a combination of two primary filtering techniques:
1. Collaborative Filtering: “People Like You Also Watched…”
This is arguably the most powerful and widely used technique. Collaborative filtering works on the principle that if two users share similar tastes in the past, they are likely to have similar tastes in the future. It identifies patterns by comparing your viewing habits with those of millions of other users.
- User-Based Collaborative Filtering: Find users whose viewing history is similar to yours. If User A and User B both enjoyed Movies X, Y, and Z, and User A then watched Movie Q, the system might recommend Movie Q to User B.
- Item-Based Collaborative Filtering: This looks for relationships between items. If many users who watched Movie X also watched Movie Y, then Movie Y is a good recommendation for someone who just watched Movie X. This is often more scalable for large datasets.
Strength: Excellent for discovering new and unexpected content that you might not have found through content-based methods alone. It taps into the collective intelligence of the user base.
Challenge: The ‘cold start problem’ for new users (no history) or new content (no watch history). Also, it can lead to ‘popularity bias’ where only widely watched content gets recommended.
2. Content-Based Filtering: “More of What You Love”
Unlike collaborative filtering, content-based filtering focuses on the attributes of the items themselves. It recommends content that is similar to what you have already enjoyed. Each movie or show is described by its features (genre, actors, director, plot keywords, themes, language, release year, etc.).
- The algorithm builds a profile of the content you like based on the features of items you’ve watched and rated highly.
- It then searches the entire content library for items with similar features.
Strength: Great for niche interests and avoids the cold start problem for new content (as long as it has rich metadata). It provides a high degree of personalization based on your explicit preferences.
Challenge: Can lead to a ‘filter bubble’ or ‘echo chamber,’ where you are only shown content very similar to what you’ve already seen, limiting discovery of diverse content. It relies heavily on accurate and comprehensive content metadata.

The Hybrid Approach: The Best of Both Worlds
Most modern streaming giants don’t rely on just one method. Instead, they employ sophisticated hybrid recommendation systems that combine collaborative and content-based techniques. This allows them to leverage the strengths of both while mitigating their weaknesses.
- Matrix Factorization: Techniques like Singular Value Decomposition (SVD) or Alternating Least Squares (ALS) are commonly used to uncover latent factors (hidden characteristics) that explain user preferences and item similarities, often forming the backbone of hybrid systems.
- Deep Learning & Neural Networks: Advanced AI models can identify incredibly complex, non-obvious patterns in vast datasets. They can learn highly nuanced representations of both users and content, leading to highly accurate and diverse recommendations.
- Contextual Bandits: These are algorithms that explore new recommendations while simultaneously exploiting known good ones, helping to balance personalization with serendipity.

Beyond the Algorithm: Real-Time Feedback and A/B Testing
It’s not just about crunching numbers once. Recommendation engines are dynamic. They are constantly learning and adapting. Every time you interact with a recommendation (or ignore it), that feedback is fed back into the system, refining future suggestions.
- Real-time Adjustments: If you start watching a new show, the algorithm might immediately pivot, suggesting more content related to that show’s genre, actors, or themes.
- A/B Testing: Streaming services constantly run experiments, showing different recommendation layouts or algorithmic variations to different user groups to see which performs best (e.g., leads to more watch time or higher satisfaction).
- Human Curation & Trends: While algorithms rule, human editors often play a role in curating collections or highlighting trending content, especially during major events or holidays. This provides a balance to purely algorithmic suggestions.

The Challenges and Future of Recommendations
Despite their sophistication, recommendation systems face ongoing challenges:
- The Cold Start Problem: As mentioned, new users and new content lack sufficient data for accurate recommendations. Services often rely on popular content or asking new users for initial preferences to combat this.
- Filter Bubbles: The risk of users being exposed only to content reinforcing their existing views, limiting discovery and potentially creating echo chambers. Algorithms are increasingly designed to introduce ‘serendipity’ to combat this.
- Privacy Concerns: The vast amount of data collected raises questions about user privacy and how this data is stored and used.
- Bias: Algorithms can inadvertently perpetuate biases present in the training data, leading to unfair or unrepresentative recommendations.
The future of streaming recommendations is likely to involve even more sophisticated AI, real-time contextual awareness, and perhaps even proactive suggestions based on your mood or activities outside the platform (with appropriate privacy safeguards, of course).
Frequently Asked Questions About Streaming Recommendations
Q1: Can I influence my streaming recommendations?
Absolutely! The most direct way is by actively rating content (liking/disliking), adding titles to your watchlist, searching for specific genres or shows, and simply watching content you enjoy. Every interaction provides valuable feedback to the algorithm.
Q2: Why do I sometimes get irrelevant recommendations?
Several factors can cause this: a new profile with limited data, a recent shift in your viewing habits not yet fully registered by the algorithm, or even licensing changes that make certain content available or unavailable. Sometimes, a service might also recommend something popular or trending, even if it doesn’t perfectly align with your usual taste, just to test the waters.
Q3: Do different family members affect each other’s recommendations?
Yes, if you share a single profile. This is why most streaming services encourage creating individual user profiles within an account. This keeps viewing histories separate, allowing each user to receive personalized recommendations tailored solely to their own habits.
Q4: How do streaming services recommend new releases when there’s no watch history?
For new content, they primarily rely on content-based filtering (matching genres, actors, themes with your past preferences) and collaborative filtering (seeing which users with similar tastes are starting to watch the new release). They also factor in popularity and marketing pushes.
Q5: Are recommendations truly unique for every user?
To a very high degree, yes. While some popular titles will appear across many users’ feeds, the specific order, mix of genres, and hidden gems presented will be highly individualized based on your unique viewing history and interactions.
The Art of Prediction
The next time you hit play on a show that feels custom-made for you, take a moment to appreciate the intricate algorithmic dance happening behind the scenes. Your next binge isn’t random; it’s a meticulously engineered prediction, designed to keep you engaged, entertained, and discovering content that resonates. It’s a testament to how artificial intelligence and data science are continuously reshaping our digital lives, one personalized recommendation at a time.
Related posts:
 Demystifying “The Algorithm”: Your Digital Sorter Explained
Demystifying “The Algorithm”: Your Digital Sorter Explained
 Watch IPL 2013 Live Online – IPL 6 Free Live Streaming
Watch IPL 2013 Live Online – IPL 6 Free Live Streaming
 Lost in the Algorithm: Understanding Online Filter Bubbles and Echo Chambers
Lost in the Algorithm: Understanding Online Filter Bubbles and Echo Chambers
 Top IPL 2013 Android Apps for IPL live scores, schedule, live streaming
Top IPL 2013 Android Apps for IPL live scores, schedule, live streaming
 The Hidden Dangers: Why Free VPN Services Aren’t Worth the Risk
The Hidden Dangers: Why Free VPN Services Aren’t Worth the Risk